
We believe in a highly accelerated transformation to a global carbon neutral circular economy. Advanced AI systems enhancing our abilities are emerging as a critical success factor to achieving an outperforming transformational momentum. Those systems need to be trained with cutting edge machine learning models (ML). A new level of challenges shows up with training those models accurately.
You can think of the 3DTWINZ TRAINBOW™ Pipeline Framework as the gym for your AI projects. Read more about it here.

Get some impressions of botanical 3D scanning quality using Gaussian Splatting that we can integrate into the 3DTWINZ TRAINBOW™ Pipeline Framework if helpful by checking out the 3D examples.

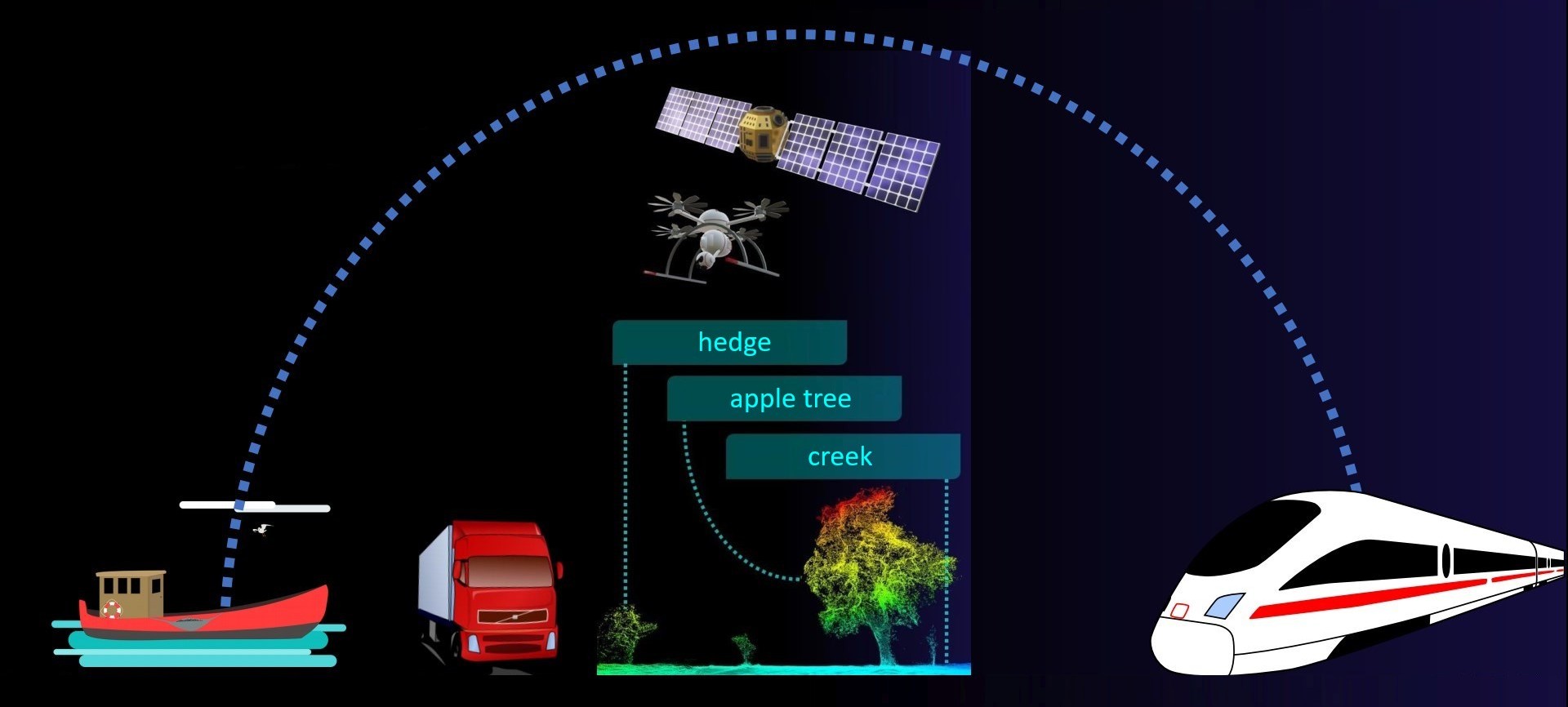
Are you struggling to find enough high-quality labeled training data for your machine learning projects? Are noisy datasets hindering the performance of your models, slowing down your progress? We understand the pressing challenges faced by AI enthusiasts and businesses alike when it comes to training robust machine learning models for object and scene recognition. That's why we compiled the 3DTWINZ 3D synthetic dataset pipeline. With this cutting-edge pipeline you can improve the abilities and quality of your ML journey while lowering cost with the availability of unlimited procedurally generated labeled traininig data. Even for complex scenes like marine scenarios or biotopes including multi- and hyperspectral as well as 3D Depth footage.
The foundation of any successful machine learning project lies in its training data. Insufficient, poorly labeled, or noisy datasets can severely hamper the accuracy and generalization capabilities of your models. The most pressing problems include:
a) Insufficient Data: Real-world data collection can be expensive, time-consuming, and limited in scope, leaving your models under-trained and unable to handle diverse scenarios.
b) Limited Labeling Resources: Manually labeling vast amounts of data demands significant human effort, leading to bottlenecks in training pipelines, potential labeling errors and high cost.
c) Noisy Data: Noise in the training data can mislead models, leading to poor decision-making and compromised accuracy in real-world applications.
Our 3D synthetic dataset pipeline offers a groundbreaking solution to address these challenges. By generating high-fidelity synthetic datasets with accurately labeled data, we enable machine learning models to excel in object and scene recognition tasks.
For this, we as Team Bio.KI.S.S. were awarded at the datarun2023 by the German Federal Minister for Digital Affairs and Transport as the most technically sophisticated approach.
The datarun2023 event: https://twitter.com/bmdv/status/1667573136844374016
Winners: https://twitter.com/bmdv/status/1667573142082973698
Interview with Joerg Osarek (German): https://bmdv.bund.de/SharedDocs/DE/Artikel/DG/datarun2023-portrait-biokiss.html
A more poetic approach to a preceding proof of concept we participated in can be found here: https://sherlock-ai.climatehackerz.com / and in German: https://sherlock-ki.climatehackerz.com
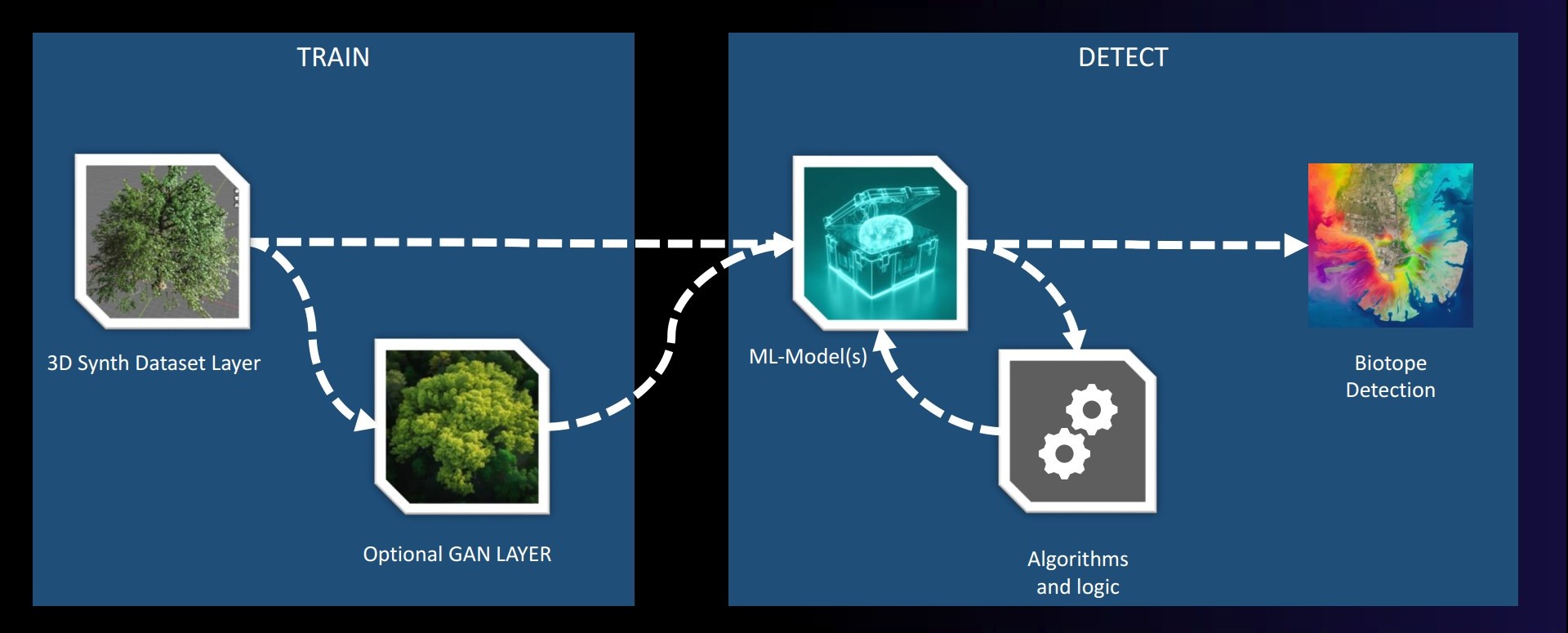
a) Unlimited Data Generation: Our cutting-edge 3D synthesis technology can create an infinite variety of realistic scenarios, providing an abundant and diverse dataset for your ML models.
b) Precise Labeling: With our carefully curated synthetic datasets, each data point comes with precise labels, guaranteeing the highest quality of training data for optimal model performance.
c) Noise-Free Environment: By eliminating real-world noise, our synthetic datasets ensure that your models can effectively discern signal from noise, leading to superior generalization and robustness.
d) Free to choose viewpoint. ML-Models trained on footage usually don't understand the third dimension. If you train to detect a forest from satellite images you will have to train it again if you want to use 1st person mobile phone images. With the 3D synthetic datasets you can just choose another viewpoint and train for that as well or use it to determine the objects (trees) and the angle (from above, 45 degrees, 1st person).
e) sometimes the mix will be the fix. As with coffee and wine sometimes the secret to good results is blending grapes or coffee beans. We can blend synthetic with real world training data to see if this improves classification as well.
f) the 3DTWINZ pipeline is built as an open source, open data blueprint. So anybody can contribute to it and act as a curator for their particular niche of interest. We proudly use the capabilities of the free Blender 3D Modeling and animation suite such as Blender Geometry Nodes for procedural object generation. This is a can, not a must. You decide what you contribute and what you want to keep proprietary.
g) Our workflow steps include: Capture reality, Create procedural 3d twins, add a GAN Layer (Generative Adversarial Network) for higher efficiency, Train, Simulate, Act
h) It doesn't end here. If you plan to use material produced with the 3DTWINZ pipeline for simulation purposes we can also look together into this.
Embracing our 3D synthetic dataset pipeline, you can expect unparalleled advantages - however it comes with a consequence:
If the success of your ML approach is based on a vast amount of training data we are the right place for you. Unlike with a traditional approach of gathering as much training data as possible at a fixed price per unit for human capturing and labeling our approach follows the principle: First think (and explore), then act. This means we have to discover the relevant real world multi channel attributes of your topic of classification upfront with a few samples - let's say some pine trees in different age and different health situations. From that we can build a generalized multi-/hyperspectral procedural 3D model generator to randomize and scatter it in various environments. From that point we can enjoy the following advantages:
a) Improved Model Quality: Vast and precisely labeled synthetic datasets can be produced for the training of your ML models.
b) Accelerated Development: Say goodbye to the tedious data collection and labeling processes. Our synthetic data pipeline allows you to train your models faster, accelerating your development cycles.
c) Cost-Effective Solution: Save time and resources by reducing the need for expensive data collection and manual labeling. Our affordable 3D synthetic datasets offer cost-effective alternatives without compromising quality.
Everyone is at a different point in their ML journey. You don't need to buy a pig in a poke. Choose the package that suits you best.

In a 45 minute remote call we can explore: Where are you today and where do you want to go with your ML pipeline and what are your top challenges where 3DTWINZ could be of help. You will receive an honest feedback whether or not we believe we can add value to your endeavour.

1 day personal remote or on site workshop for a small group. This one day workshop is about your personal ML journey. We cover:

Interested? Then feel invited to mail us at: contact at climatehackerz dot com or call Joerg Osarek: +49-151-23 0 24 333.